Performance Diagnostics: Cross-Layer Optimization of Web DRM Reader

Background
NoteX is a digital educational workbook platform that helps individual creators legally and safely sell educational materials without a registered legal entity, through a collective licensing agency model. This case study focuses not on feature development, but on "establishing a verifiable performance diagnostic system within an uncertain and resource-constrained environment."
Market challenges:
• Individual creators lack legal entity status, making it difficult to sell materials through legal channels.
• High risk of piracy for educational content
• Traditional e-commerce platforms cannot protect intellectual property rights
Project strategy:
• Centralize licensing and publishing workflows under a legal entity
• Build a proprietary Web DRM reader as the core delivery interface
• The reader serves as the copyright protection layer, restricting illegal copying and distribution in the browser
Technical scope and my role:
• Infrastructure: WordPress + WooCommerce
• Responsibilities: Web DRM reader development and integration
• Development strategy: Rapid prototyping with Lovable AI tools → Technical validation → Integration into WordPress
Challenges
- Unexpected performance issues after integration
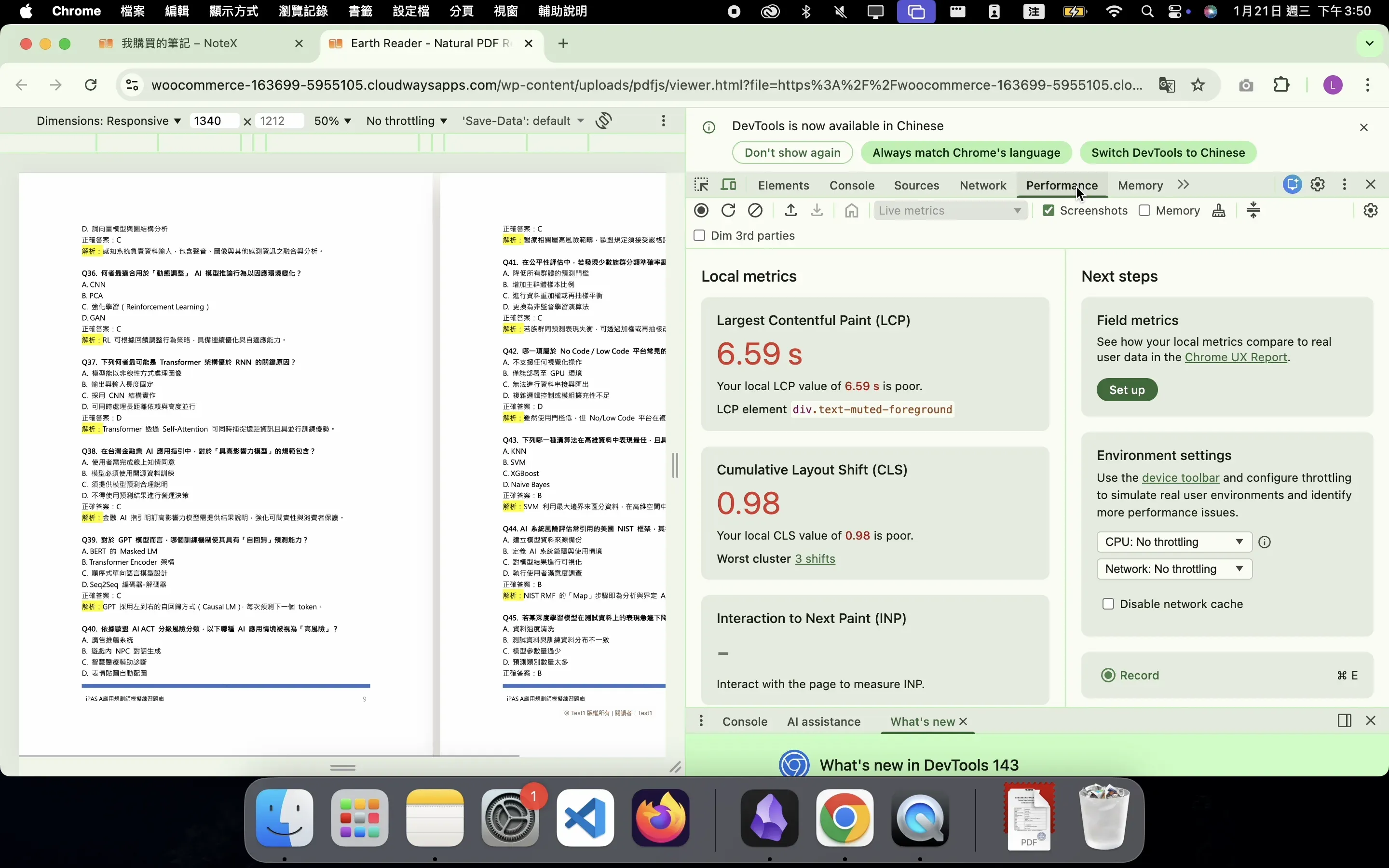
The client reported that "everything feels slow," but performance remained poor, with PDF load times (LCP) reaching 6.59s even after implementing Blob-based client-side caching. The problem spanned the frontend, backend, and browser caching mechanisms, requiring cross-layer diagnosis to identify the root cause. - WordPress caching strategy design
The system spans WordPress's EAV structure and custom tables (annotations, reading progress, bookmarks). Different data characteristics require different caching strategies, balancing real-time responsiveness with performance.
Actions
- Identifying the Problem
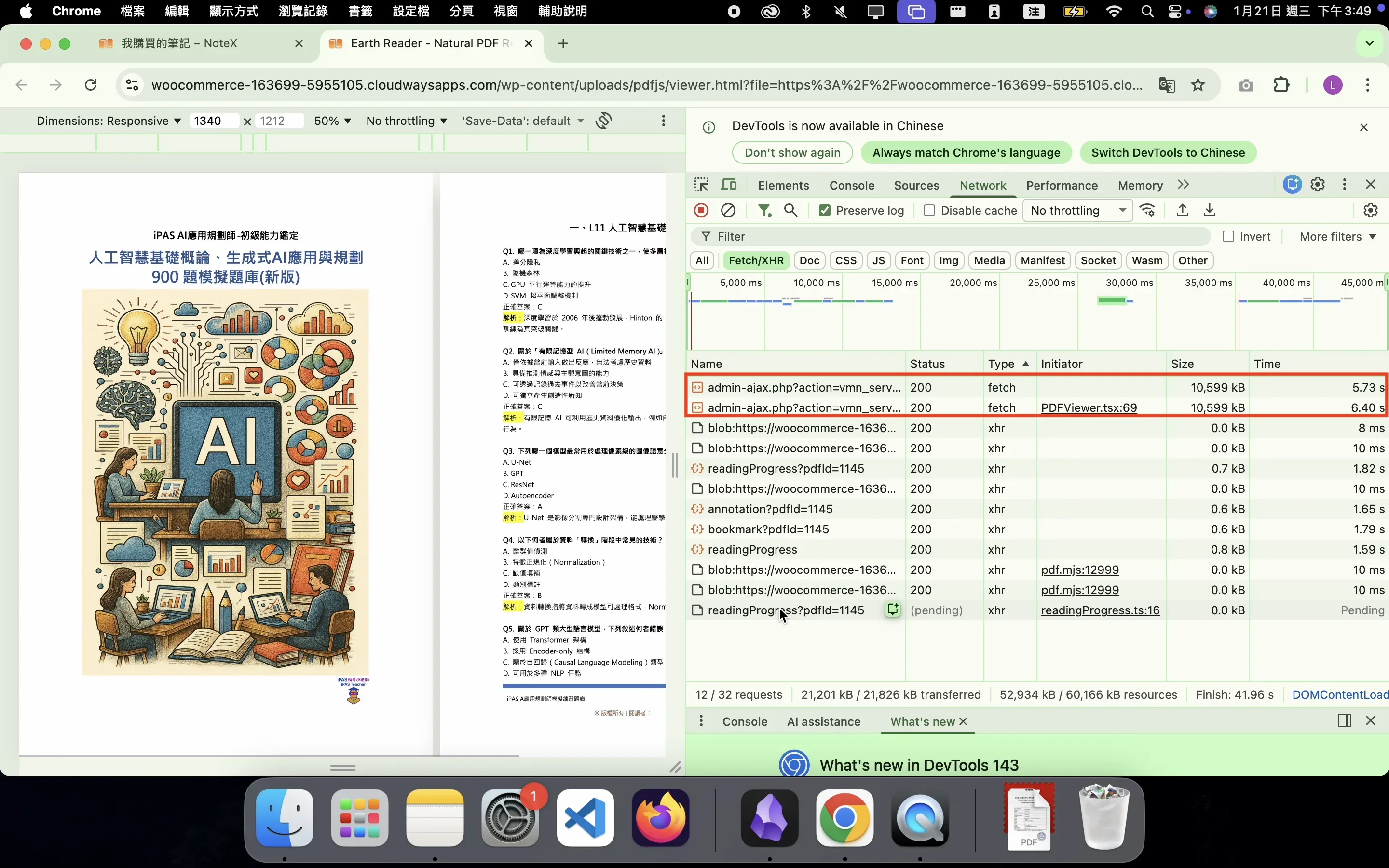
Network logs revealed redundant downloads of large PDF files—for instance, a 10MB file being fetched twice, taking 5.73s and 6.40s respectively. Since Blob-based caching was implemented correctly, I ruled out frontend issues and determined that the bottleneck stemmed from the HTTP caching strategy rather than the frontend request mechanism. - Hypothesis Validation
Designed an A/B test to validate the hypothesis:
• A: No Blob, with Header (baseline)
• B-1: With Blob, no Header (testing Blob benefit in isolation)
• B-2: With Blob, with Header (final solution) Observed LCP, request count, and disk cache behavior. - Decision and Implementation
Backend HTTP layer Header caching:
• PDF files:Cache-Control: public, max-age=86400→ long-term caching
• APIs (progress/bookmarks/notes):Cache-Control: no-cache, must-revalidate→ real-time sync WordPress Transient API: 30-second cache, balancing performance and real-time responsiveness.
Execution
- Case A|Full Reasoning Chain of Performance Diagnosis
Trigger: The project's features were complete, but after full integration the client reported "the reading experience feels slow." With the feature layer stable, this task focused on identifying the actual source of the performance bottleneck rather than revisiting feature design.
Phase 1: Initial Observation — Identifying Anomalous Behavior
Reviewing network logs in B-1 mode (Blob enabled, no Cache Header), a large 10MB PDF was being downloaded twice. Since the Blob was correctly initialized, frontend issues were ruled out.Request Status Size Time 1st admin-ajax.php 200 10,599 kB 5.73s 2nd admin-ajax.php 200 10,599 kB 6.40s LCP — — 6.59s
Phase 2: Hypothesis Formation and Controlled Testing
• Subjects: B-1 (no Header) vs B-2 (with Header) modes
• Hypothesis: The bottleneck is not Blob itself, but insufficient information at the HTTP caching layer
• Finding: B-2 → first download + disk cache 103ms, LCP dropped to 0.60s
• Inference: Missing Cache-Control / ETag prevented the browser from determining whether content was cacheableTest Mode First Request Second Request LCP B-1 (no Header) 5.73s download 6.40s download ❌ 6.59s B-2 (with Header) 4.60s download 103ms disk cache ✅ 0.60s
Phase 3: Controlled Variable Validation
• Subjects: Mode A (no Blob, with Header) vs B-2 (Blob + Header)
• Hypothesis: With correct HTTP Cache Headers, can Blob reduce duplicate requests?
• Finding: B-2 (Blob + Header) strategy
- A (no Blob, with Header): 4 initial requests
- B-2 (Blob + Header): 2 initial requests
• Conclusion: B-2 combination strategy yields the best resultsTest Mode Initial Load Requests Disk Cache Behavior A (no Blob, with Header) 4 (1 download + 3 disk cache) 3.74s, 3.66s, 28ms, 19ms, 2ms, 1ms B-2 (Blob + Header) 2 (1 download + 1 disk cache) 103ms
- Case B|WordPress Caching Strategy Decision
Differentiated caching strategy by data characteristics:
• HTTP layer: Long-term caching for PDF files (24h); no caching for data APIs (cross-device sync)
• Application layer: Transient API short-term cache (30s), balancing performance and real-time responsiveness
Result: API execution time < 1ms, cache hit rate 100% (within 30s)
Results
- Performance improvement
• LCP from 6.59s → 0.60s (+91%), initial request count 4 → 2 - Technical methodology
• Established a repeatable performance diagnosis process (Observe → Hypothesize → Validate → Implement) - Professional capabilities
• Cross-layer analysis, verifiable technical decisions, decomposing problems under uncertainty
Reflections
- Redefining Engineering Responsibility
This project redefined for me what engineering responsibility means: it's not just completing features, but being able to explain the causal relationship between performance behavior and user experience. The project taught me to proactively clarify responsibilities across the frontend, backend, and environment layers, and to set clear risk boundaries when resources are limited. - Building a transferable engineering decision framework
In NoteX, I treated the performance problem as a system behavior that could be reasoned about and verified, not a singular technical error. The process I built: observe anomaly → form hypothesis → design controlled experiment → validate difference → set stopping criteria. This method doesn't depend on a specific framework or technology—it's used to quickly identify the problem layer, avoid over-optimization, and make engineering decisions that can be traced and explained, in contexts that are uncertain, poorly documented, or have ambiguous responsibility boundaries. - Internalizing professional transformation
The Taoyuan Smart Streetlight project trained me to handle uncertainty at the governance level; NoteX let me practice the same capability at the technical level: building a verifiable methodology in an undefined context. This has become my core professional capability across PM and Engineering, and allows me to make sound decisions in uncertain scenarios.
Smart City Governance: PFI Digital Transformation in Taoyuan
Unified four legacy systems into a single platform through governance design and role-based access control, serving six user types and managing 162,000 smart streetlights across Taoyuan.
Spatial Data Integration: Disclosing 202 Unregistered High-Risk Segments
Engineered Taipei’s first spatial validation system to automate the identification of 202 unregistered risk segments, achieving a full integration of 1,672 segments totaling 9.18 km.